
前言:基于RNN的文本生成器涉及到很多知识点,本文结合一个比较小的例子进行整个生成模型的流程总结,只涉及思路,不包含算法和代码,目的是理清整个预处理、训练、生成预测的流程。
例子
1 | 这短短的一生,我们最终都会失去。你不妨大胆一些,爱一个人,攀一座山,追一个梦。 |
这里选择了电影《大鱼海棠》中一句很经典的台词作为示例,进行整个流程的总结。最终的目的是让我们的模型能够自动生成该句子。
数据预处理
在目前深度学习框架如同雨后春笋般萌生的时代里,深度学习模型的搭建本身不再是高门槛的事情,相比之下数据预处理却是一个尤为重要且直接关系到最终生成结果的一环。
分词
一句话,一篇文章,我们要训练它,首先需要把它变成结构化、计算机可理解的序列。
这里我们就需要将上面的这段话进行拆分为很多个词,以供下一步处理。而我们常用的拆词有两种方式,基于char和基于word(对应到中文就是基于字和基于词),下面将展开说明两种拆词方式。
基于char分词
最直观的看这种拆词方式,直接看拆分的结果:
1 | ['这', '短', '短', '的', '一', '生', ',', '我', '们', '最', '终', '都', '会', '失', '去', '。', '你', '不', '妨', '大', '胆', '一', '些', ',', '爱', '一', '个', '人', ',', '攀', '一', '座', '山', ',', '追', '一', '个', '梦', '。'] |
这种方式中的一个字、一个标点符号、一个空格、一个换行符,都是一个独立的词,我们都要进行统计。同时,在拆词时我们还需要对每个词进行词频统计并按照词频从高到低进行排序,以供接下来的去词使用,我们统计得出如下的结果
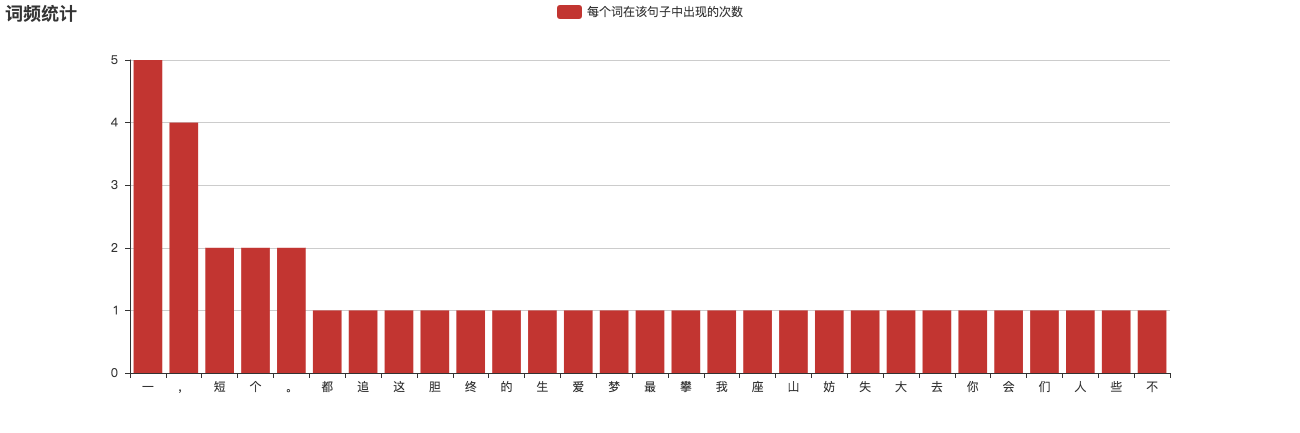
基于word分词
基于词进行拆分的方式是指拆分后的句子中会直接包含一些词语而非单字。对于英文就是一个单词,对于中文可以是一个字,也可以是一个词语。如果是一个词语,那该词语一定是确实有含义的而非任意进行组合。比如基于该示例进行的拆词结果:
1 | ['这', '短短的', '一生', ',', '我们', '最终', '都', '会', '失去', '。', '你', '不妨', '大胆', '一些', ',', '爱', '一个', '人', ',', '攀', '一座', '山', ',', '追', '一个', '梦', '。'] |
对应的词频统计如下
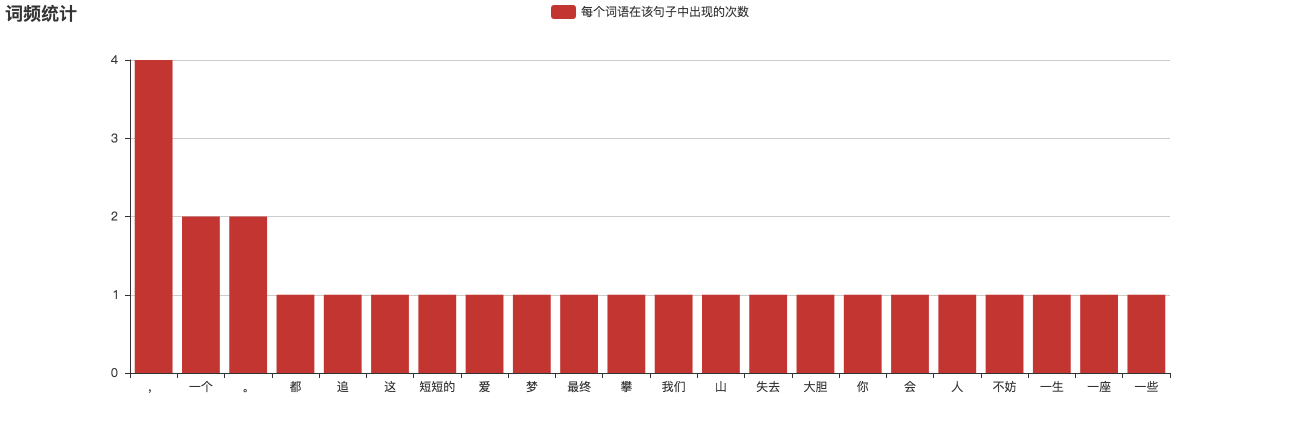
去词
在本示例汇总,去词步骤是可以省略的,因为总次数特别少。但对于几百M、甚至几十G的文本而言,该步骤会显得尤为重要。如果一本小说中有5000个字(去重后),但可能其有1000个词只出现过10次以下的,这部分词我们需要剔除掉,因为对于整个庞大的数据集而言这种低频次的词是可以忽略不计的。从这个维度来说只能说明保留低频词的不必要性,而实际上,我们还需要从另一维度来说明取出低频词的必要性,那就是防止维度爆炸,关于这一点会在后面提到。
数据映射
上面提到我们需要将数据转化为计算机可理解的序列,而实际上仅仅将句子转化为词的层面上,还是不够的。我们需要对词在进行数字形式的离散化,以便后面我们的模型能够进行识别。
这里我们就以上面基于char分词的结果进行映射选择,我们的词和数字索引的映射关系是这样的:
1 | "一": 0 |
该映射关系非常重要,将纵向贯穿到接下来的数据处理、模型训练和最后的模型预测的整个流程。由于该映射关系是标识词 => 词索引的,所以我们简称之为word2index;相反的,我们还需要一个词索引 => 词的反向映射关系,即0: "一", 1: ",", 2: "短", …这种形式的映射关系,我们简称之为index2word。
数据对齐
宏观来说,RNN模型是专门用来处理序列数据的,它最大的优势就是能够打破普通神经网络中维度固定的限制;但微观来说,RNN模型的基本单元又是一个个基本的神经元组成的,所以更小范畴内来看,在数据处理方面还是需要对训练数据进行数据对齐操作的。
具体的对齐操作是指我们根据指定长度(比如5)的词作为输入,前面不足该长度的用起始符(这里用【)代替,该输入序列的下一词会作为对应的输出,然后再结合该输出作为下次预测的输入继续进行预测,直到预测到结束符(这里用】标识)为止,便完成了一整个预测流程。
1 | ['【', '【', '【', '【', '【'] => '这' |
上面的映射关系是为了便于我们理解而写的形式,而实际上提供给我们模型学习的数据是通过上面的word2index映射的数据。如下:
1 | ['39', '39', '39', '39', '39'] => ' 7' |
由于index形式的数据可读性不好,就不一一展示出来了。
注:word形式的数据到index形式的数据需要特别注意的一点是,
【和】这两个标识符在word2index中是没有对应的index的,这个时候需要我们来约定一种映射关系:起始符对应总词数,结束符对应总词数 + 1。比如对于本例公有有39个词,那词索引范围就是0-38,此时起始符就对应总词数39,结束符就对应总次数39+1=40。
模型训练
数据供给方式
数据供给是指预处理后的数据供给模型进行训练,一般的数据供给的方式有两种:全量供给和基于生成器的供给。
全量
顾名思义,全量供给是指一次性把所有的数据全部提供给模型,告诉模型如何每次吃下多少(batch_size)条数据,然后模型自己会每次从中去取。
该方式的好处是数据供给方便,不需要过多的计算steps_per_epoch和batch_size的关系;缺点就是会占用全量训练数据的内存,所以对于小数据集的数据推荐使用该方式。
生成器
基于生成器模式的数据提供,它实际上是采用了懒加载的方式,模型通过迭代来取到下一batch的数据,生成器方式的数据供给可以通过Python语言的yield关键词来配合完成。
由于数据是懒加载的,因此该方式的好处是极大程度节省内存占用;当然对应的缺点就是实现的成本要高于前者,且需要计算出steps_per_epoch来间接告诉模型总数据量。(在CV方向的DL模型中基本上都会使用该方式。)
模型预测
初始数据
模型预测时可以选择一个”引子”作为模型初始状态的上下文,比如把”这短短的一”;当然也可以不选择,让模型自动预测,以作为下次迭代的上下文。
预测
和模型训练时不同的是,预测时我们只需要把batch_size设置为1即可,因为我们只需要预测当前的上下文出现的下一个词。
结果选择
模型最终预测的结果是一个(n_words + 2, )形式的numpy数组,其中每个元素就代表预测下一个词(或者是起始/结束符)的概率值。比如[0.1, 0.03, 0.7, ...]就表示0的概率是0.1,1的概率是0.03,2的概率是0.7,这里的0、1、2对应的就是预处理阶段的词索引,即对应一个词。
此时我们一般会按照预测的词概率进行选词,而非直接去选择概率最高的那个词。因为模型训练后的参数是固定的,如果”引子”数据也是固定的,那直接选择概率最高的词就会导致每次预测的结果是完全一样的,这有悖于我们要希望生成样本多样性的初衷。
迭代预测
与预处理阶段的方式相同,我们每次都会将当前这次的输出结果并入到下次预测的输入,从而进入下次预测。比如当前的上下文是这短短,对应的预测结果是的,那下一次预测的上下文就是这短短的。