
在日常工作当中,我们经常会和浏览器打交道,当然就可能会在浏览器上做一些重复、无脑的工作,这篇文章旨在对于这类问题出一个基于脚本的自动化解决方案。
Selenium库
简要
一句话概括,Selenium就是一个浏览器自动化测试框架。它支持包括IE、Chrome、Mozilla Firefox、Mozilla Suite在内的大多数主流浏览器。当然本文主要讲述的并不是关于它在自动化测试部分方面的运用,该部分在Selenium官网和网上各种Blog处均有很多也很详细的介绍,这里我们要说的是基于它的浏览器控制能力来演化出的另一个应用方向——自动化处理任务。
快速开始
安装
首先,在拥有python环境的os中命令行执行 pip install selenium 来安装Selenium库。(Mac os直接安装时可能会出现权限问题,此时尝试命令前面添加sudo,还不行时则需要尝试通过创建Python沙盒的方式来安装。)
其次,下载一个跟自己浏览器和版本对应的webdriver,然后将该文件配置在环境变量下。比如Chrome浏览器的webdriver就在这里下载。这里需要注意下载的webdriver版本不是越新越好,而是要下载跟自己浏览器版本匹配的。我首次安装时在这里踩过坑。具体查看匹配的方式是打开Chrome => 点击菜单Chrome => 关于Google Chrome,在该界面能看到自己浏览器的版本。然后进入在上面的下载页面找到与自己版本匹配的webdriver,具体比较的地方在此处
最后测试下是否配置正确,终端打开一个新窗口,输入命令chromedriver -v执行,如果配置没问题,此时便能看到webdriver的版本号,如下
1 | ➜ ~ cd Documents/libs |
快速开始
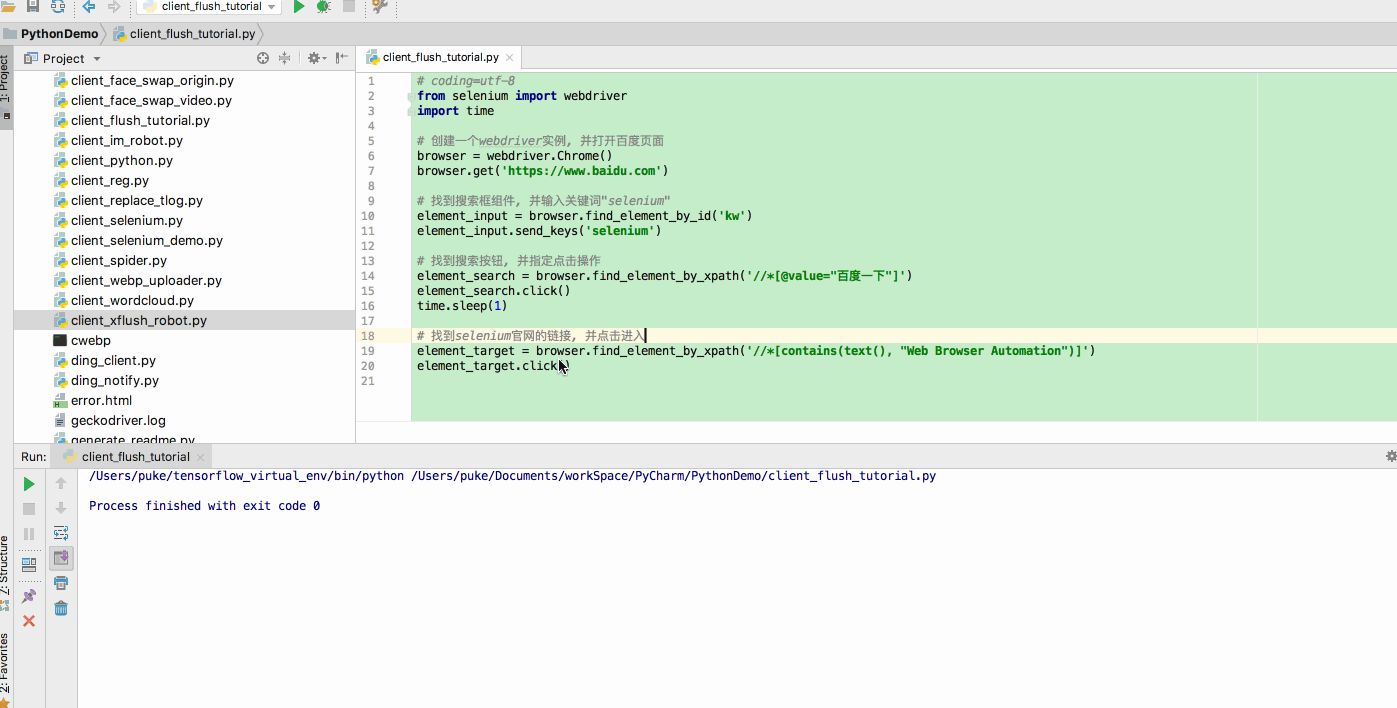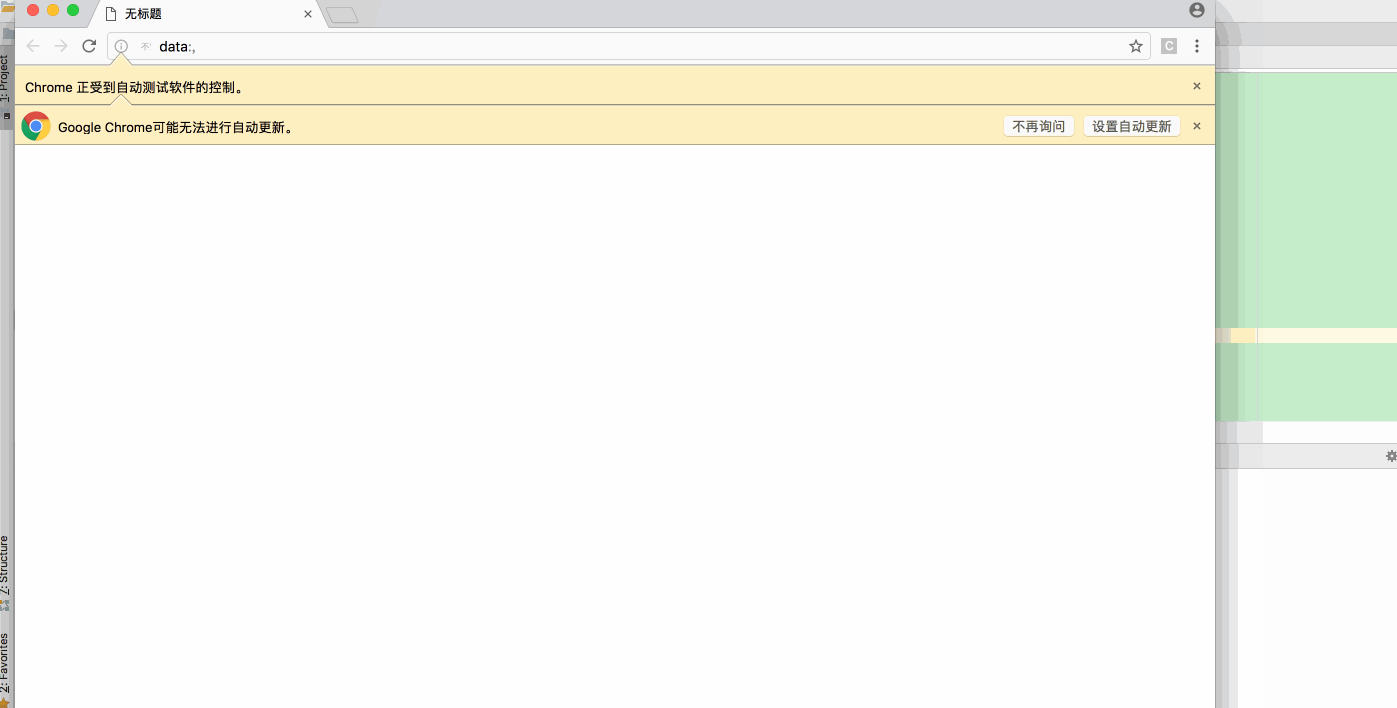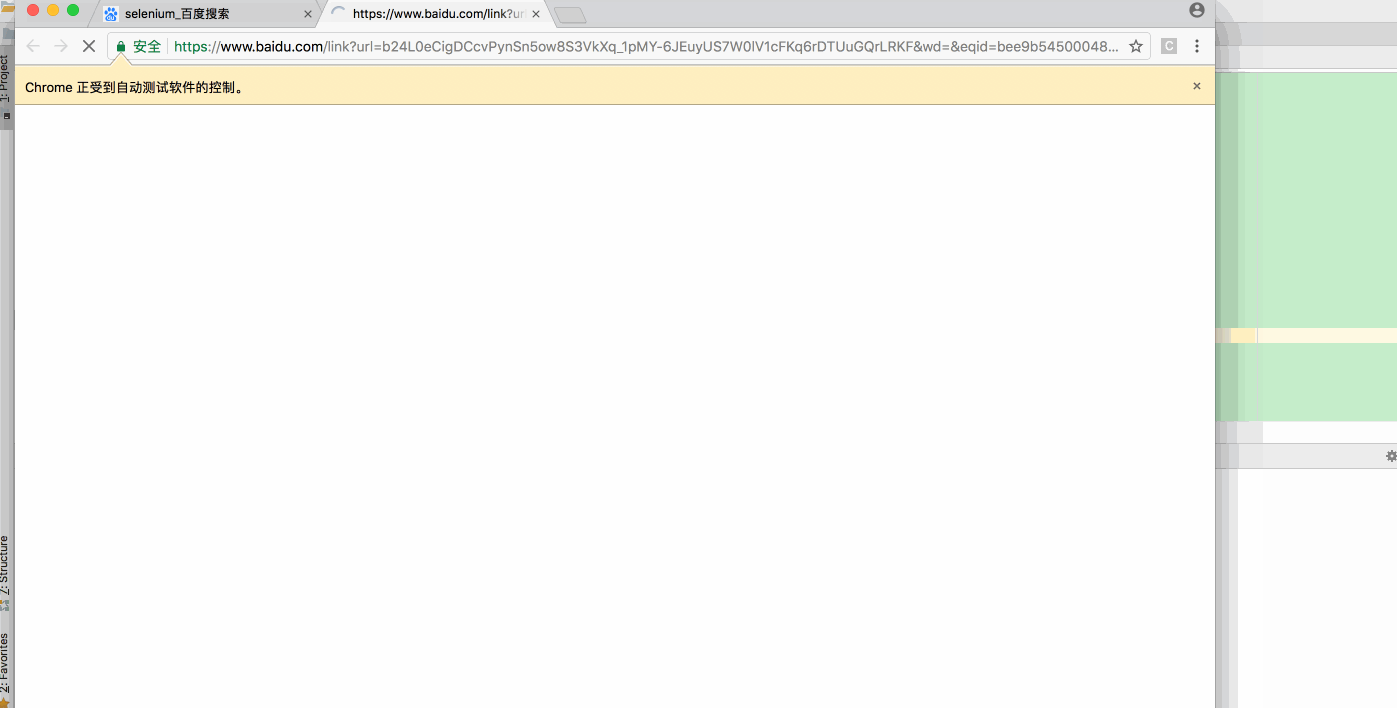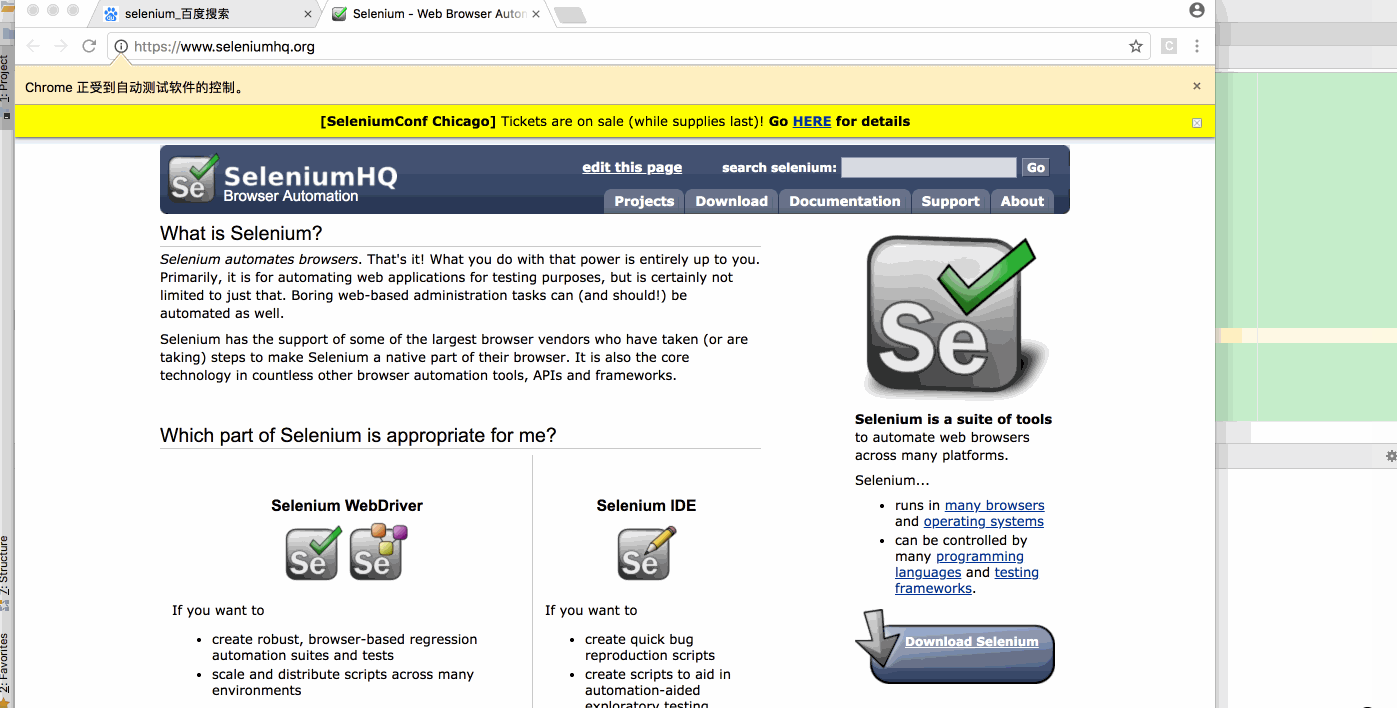
环境配置完成之后,来通过一个简单的百度搜索然后进入Selenium官网的Demo来看看Selenium的实际运行效果。新建client_selenium.py脚本文件,然后执行添加如下代码
1 | # coding=utf-8 |
执行该python文件后,脚本会通过webdriver来去驱动浏览器进行一系列的打开、输入、点击等操作,如下图
常用api
Selenium库具有很丰富的api,但对于只需要写任务处理脚本而言,我们只需要了解一些比较核心高频的api,下面列举出常用的api
| 操作 | api | 说明 |
|---|---|---|
| 输入 | send_keys('Hello') |
输入文本 |
| 点击 | click() |
执行点击 |
| 查找元素 | find_element_by_id() |
根据ID进查找 |
| 查找元素 | find_element_by_name() |
根据name查找 |
| 查找元素 | find_element_by_tag_name() |
根据标签查找 |
| 查找元素 | find_element_by_link_text() |
根据链接文本查找 |
| 查找元素 | find_element_by_class_name() |
根据class名查找 |
| 查找元素 | find_elements_by_css_selector() |
根据css选择器查找 |
| 查找元素 | find_elements_by_xpath() |
根据xpath语法查找 |
可以看到,其中Selenium库包含丰富的元素查找相关的api,找到对应的元素是对该元素进行操作的基础,所以能否快速、便捷、精准的查找到目标元素至关重要。
这里着重强调一下find_elements_by_xpath函数,该函数是基于XPath语法规范进行查找元素的,该规范在爬虫开发、浏览器脚本、XML配置查找等方面的使用时相当高频的。实际上,上面的所有查找方法都可以通过该方法进行替代。
应用
(涉及到公司业务保密,这里就不展示出来了)
拓展
用原生Selenium的Api写过一个应用之后,虽然感觉它的Api不算复杂,但对于我们只想写一个自动化脚本而言,还是不够简练,毕竟它的Api的初衷是给为了做浏览器自动化测试使用的。
而我想要的效果就是,更简单,尽可能一行代码执行一个Action,而一个自动化脚本就是包含多个Action的一个Robot。于是就基于Selenium库封装了很薄的一层selenium-robot库,然后发布到pypi仓库里。
以最上面的访问Selenium官网的那个Demo来比较,用selenium-robot来实现出来的是这样的
1 | from selenium_robot.actions import * |
代码量减少了一半多,最终运行的效果是一样的,对于自动化脚本的开发可以更加便捷、高效。
总结
总的来说,基于上面的Selenium库,我们还能开发出很多自动化脚本:
可以把工作中重复的配置操作通过该方式完成,这种工作在运营人员面前应该不少,比如要配置N个活动,每天配置广告Banner,配置公告信息等;
可以结合某些xml解析库进行爬虫开发,而且这种爬虫是基于浏览器驱动进行数据爬取的,而非像Scrapy等这种基于纯数据角度的爬虫框架一样。人家是模拟浏览器请求,Selenium模拟都不模拟了,自己干脆直接驱动浏览器,这样几乎不会被反爬工具监测到;
脑洞再大一些,甚至还可以写网页版游戏的外挂等等。